
🧬 LangGraph教程(三):为你的Agent添加记忆(Checkpoint持久化与Mem0)
本文是 《LangGraph入门全解》LangGraph入门指南:从基础ChatBot到多智能体实战 系列的第三篇。在这篇文章中,我们为聊天机器人增加长短期记忆能力,并使用redis持久化记忆。以及使用Mem0为chat bot增加用户级别的记忆。如果出你是新手,建议先阅读主指南以了解LangGraph的全貌。
三、在LangGraph中添加记忆
我们简单区分为任务级别记忆、用户级别记忆,或短期记忆、长期记忆
- 任务级别记忆(Checkpointing):适合短期会话和任务流程的状态保存,轻量易用。
- 用户级别记忆(Mem0):适合需要长期交互和个性化体验的应用,比如智能客服、AI 助手。
两者结合,在不同层面增强 LangGraph 应用的智能化和可持续性。
任务级记忆
在LangGraph中又被称为检查点(checkpointing),它是 LangGraph 能够支持 长周期任务执行 和 断点续执行 的关键机制。
在前两节中,我们通过手动维护一个 messages 列表来实现多轮对话。然而,这种方式在面对 多用户、多任务 以及 复杂图结构 时,维护成本会急剧上升。
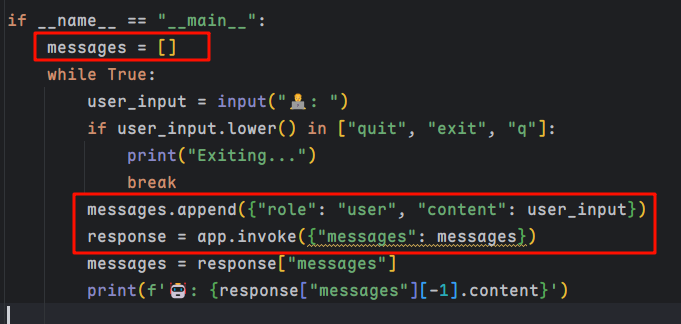
添加记忆模块
为了解决这一问题,LangGraph 提供了更为简洁的记忆模块。只需修改3行代码,就能启用内存记忆:
from langgraph.checkpoint.memory import InMemorySaver memory = InMemorySaver() # ...省略重复代码 app = graph_builder.compile(checkpointer=memory)
在调用时,只需配置 thread_id:
# ...省略重复代码,注意 config thread_id的配置 response = app.invoke({"messages": {"role": "user", "content": user_input}}, config = {"configurable": {"thread_id": "1"}})
这样便实现了基于内存的记忆。但需要注意的是:一旦程序重启,记忆会丢失。
使用 Redis 持久化记忆
为了避免重启导致数据丢失,我们可以改用 Redis 作为记忆存储。只要 Redis 保持正常运行,记忆就能持续存在。
-
安装医依赖
pip install langgraph-checkpoint-redis -
修改代码:
from redis import Redis from langgraph.checkpoint.redis import RedisSaver redis_client = Redis( host="127.0.0.1", port=6379, password="Tali1234" ) memory = RedisSaver(redis_client=redis_client)
Redis 中的存储内容大致如下:
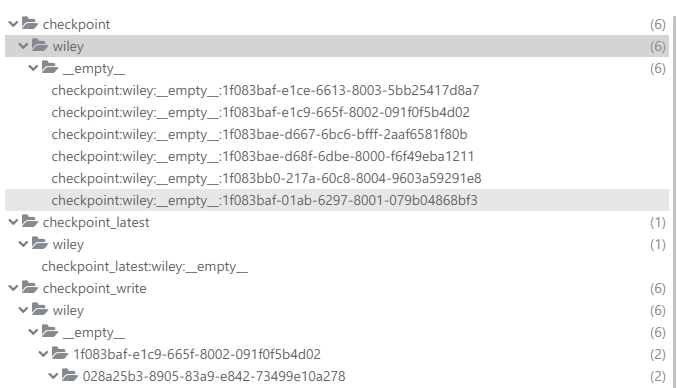
在 PyPI 上搜索 langgraph-checkpoint,还能发现更多数据库的存储实现,方便不同场景使用。
效果如下

LangGraph集成Mem0(用户级别记忆)
任务级别记忆帮助我们保持单个对话的上下文, Mem0 更进一步,提供了 跨任务、跨会话的用户级别记忆。
Mem0 是一个轻量化、模块化的智能记忆层框架,其目标是:
“通过保留用户偏好与上下文信息,随着时间推移不断适应,提供个性化和高效的交互体验。”
它支持 对话层、用户层和 Agent 层 的多层记忆组织方式,常用于聊天机器人、RPA 自动化助手、AI Copilot 等场景。
Mem0 的记忆流程分为 提取 和 更新 两个阶段:
- 在提取阶段,系统会从 最新对话、滚动摘要、最近 m 条对话 中抓取关键信息,并借助 LLM 生成简洁候选记忆。
- 在后台,长期摘要会异步更新,从而保证推理流程不会被打断。
更多内容,见之前的专题文章https://mp.weixin.qq.com/s/rqnd8nVtdtH2DXS4xhGQhQ
安装 Mem0
pip install mem0ai
示例代码(核心逻辑已标注)
from typing import Annotated from typing_extensions import TypedDict from langchain_openai import ChatOpenAI from langgraph.graph import StateGraph, START from langgraph.graph.message import add_messages from langchain_tavily import TavilySearch from langgraph.prebuilt import ToolNode, tools_condition from mem0 import Memory from langchain_openai import OpenAIEmbeddings openai_embeddings = OpenAIEmbeddings( model="gte-large-zh", check_embedding_ctx_length=False ) # 此处定义你自己的模型 llm = ChatOpenAI(model="qwen3_32") # 定义工具 tool = TavilySearch(max_results=2) tools = [tool] # 工具绑定到模型 llm_with_tools = llm.bind_tools(tools) # 创建Mem0记忆配置 config = { "vector_store": { "provider": "milvus", "config": { "collection_name": "mem0", "embedding_model_dims": "1024", "url": "http://127.0.0.1:9530", "token": "root:root", }, }, "embedder": { "provider": "langchain", "config": { "model": openai_embeddings, }, }, "llm": { "provider": "openai", "config": { "model": "qwen3_32", "temperature": 0.2, "max_tokens": 20000, }, }, } memory = Memory.from_config(config) # 定义图状态 class State(TypedDict): messages: Annotated[list, add_messages] # 此处维护完整的消息历史 mem0_user_id: str # 增加用户id graph = StateGraph(State) def chatbot(state: State): messages = state["messages"] user_id = state["mem0_user_id"] # 检索记忆 memories = memory.search(messages[-1].content, user_id=user_id) context = "Relevant information from previous conversations:\n" for m in memories.get("results", []): context += f"- {m['memory']}\n" system_message = {"role":"system", "content": f"""You are a helpful customer support assistant. Use the provided context to personalize your responses and remember user preferences and past interactions. {context}"""} full_messages = [system_message] + messages response = llm_with_tools.invoke(full_messages) # 存储记忆 memory.add( f"User: {messages[-1].content}\nAssistant: {response.content}", user_id=user_id ) return {"messages": [response]} # 使用LangGraph提供的工具节点 tool_node = ToolNode(tools=tools) graph.add_node("chatbot", chatbot) # 添加工具节点 graph.add_node("tools", tool_node) # 添加工具 条件分支 graph.add_conditional_edges( "chatbot", tools_condition, ) graph.add_edge("tools", "chatbot") graph.add_edge(START, "chatbot") app = graph.compile() if __name__ == "__main__": while True: user_input = input("👨💻: ") if user_input.lower() in ["quit", "exit", "q"]: print("Exiting...") break response = app.invoke({"messages": {"role": "user", "content": user_input}, "mem0_user_id":"mem0_wiley"}) messages = response["messages"] print(f'🤖: {response["messages"][-1].content}')
效果如下
